NLVL(Natural Language Video Localization) 이라는 task 에 관한 survey paper 이다.
I. INTRODUCTION
- NLVL 은 video 와 query sentence 가 주어졌을때, video 로부터 query sentence 내용에 관련있는 segment 만을 찾아내는 task 이다.
- NLVL == moment retrieval == moment localization == video grounding
- NLVL != Temporal Action Localization, Video Captioning, Temporal Action Proposals
- application :
- automatically cut a compilation from many videos
- locate the movie episode you want to watch most
- extract the most heplful segment from hours of surveilance
- challenges :
- intractable to align semantic info from both visual and textual modalities
- kinda hard to obtain a final timestamp from the alignment relationship
- evaluation aspects :
- Precision : THERE ARE STILL BIG GAP BWTN SOTA AND INDUSTRIAL NEEDS
- Efficiency : KEEPING ACCURACY WITH LOW COST OF COMPUTATION IS NEEDED
- Robustness : CAN THE MODEL DESIGNED FOR SHORT VIDEO LENGTH BE EASILY EXTENDED TO LONGER VIDEOS?
II. PIPELINE

- 1. FEATURE EXTRACTION
- Video Feature Extraction
- type 1 : based on the clip level : input multiple frames, output a feature vector for capturing dynamic info ex.C3D, I3D
- type 2 : based on the frame level : feature vector outputs from one frame ex. VGG, Faster-RCNN
( clip == smallest unit of video features, 최소 단위 이지만, 약간 최소 단위의 덩어리 느낌 )
( frame == spacial case of the clip , 말 그대로 이미지 한장, 아주 극단적으로 얇은 clip )
- Text Feature Extraction
- type 1 : extract whole sentence feature
- type 2 : extract the features of words separately and do more processing
- 2. CROSS-MODAL INTERACTION
- role : to allow video features text features to perceive each other
- unique design by researchers
- main method : attention mechanism, GNN
- 3. LOCALIZATION POLICIES; 내용 이해하려면 논문 읽기 요망
- to generate prediction bounds
- (1) Proposal-Based Methods :
- (2) Dense Locators :
- (3) Single-Shot :
- (4) Reinforcement Learning :
- (5) Boundary Aware :
III. CATEGORIES OF NLVL; 내용 이해하려면 논문 읽기 요망
- supervised methods
- proposal-based methods :
- dense locator :
- single-shot :
- reinforcement learning :
- boundary aware :
- weakly-supervised methods
IV. DATASETS AND EVALUATION
- datasets
- DiDeMo :
- TACoS :
- Charades-STA :
- ActivityNet Captions :
- evaluation
- R@n, IoU=m == R(m,n)
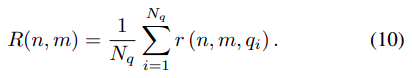
- r(n,m,q_i) : 1(exist return in which IOU > m) (n : # of timespens prediction(pred 총 길이 합인지, 아니면 pred box 개수 인지? - 뇌피셜은 pred box 개수,왜냐하면 real world 에서는 video length variance 크므로, 그 안에서 pred 총 길이가 일정하도록 모델을 만드는 것은 의미 x, 만약 어떤 영상은 매우 길고, gt 도 상당히 긴 그런 data point 가 있다면? pred 총 길이 고정은 이러한 data 의 variety 를 handling 하기 어려울 듯 ), m : margin, q_i : i th quary)
V. PERFORMANCE COMPARISON
VI. CONCLUSION AND PERSPECTIVES
'기술' 카테고리의 다른 글
| conda 사용법 (0) | 2023.09.18 |
|---|---|
| 파이토치 GPU 로 돌리기, pytorch gpu (0) | 2022.08.19 |
| 리눅스 우분투 18.04, 20.04 한글키보드 linux ubuntu 18.04, 20.04 (0) | 2022.08.01 |
| 파이토치 설치를 위한 CUDA + cuDNN 설치(cuda toolkit 11.3.0, cudnn v8.2.0) + CUDA 버전 바꾸기 (0) | 2022.03.08 |
| resnet 논문 구현 (0) | 2022.02.15 |